引言
近几日群友向我展示了GPT-SoVITS的效果,逐产生兴趣,向群友要了训练好的模型,就有了下文。
推理篇
出于对于原作者的尊重,我不在这里放下载链接。
Windows用户可以直接访问这里找到下载整合包的链接。
Linux用户请阅读并跟随这个教程,macOS没试过懒得管。
给到我的训练好的模型文件夹下有三个文件,分别是 .ckpt (GPT_Weights),.pth (SoVITS_Weights),还有一段 mp3 格式的参考音频。
Linux部署
不同发行版安装 conda,NVIDIA驱动,CUDA等的方式不同。故在此不做记录,相信到家都足够聪明知道怎么装qwq。
直入主题。
克隆仓库
git clone https://github.com/RVC-Boss/GPT-SoVITS
配置conda环境
引用自 31/7/2024 的 此处,请注意时效性
conda create -n GPTSoVits python=3.9
conda activate GPTSoVits
bash install.sh
进入目录,启动WebUI
cd GPT-SoVITS
python webui.py
推理
直接参考 这部分
Windows部署
没什么好说的,从Github找到整合包链接,下载,解压(不想教,不会的建议退出),准备好训练好的模型,分别按照扩展名放入 GPT_Weights 和 SoVITS_Weights 目录下。
运行目录下的 go-webui.bat 启动脚本。
推理
打开WebUI后进入 1-GPT-SOVITS-TTS
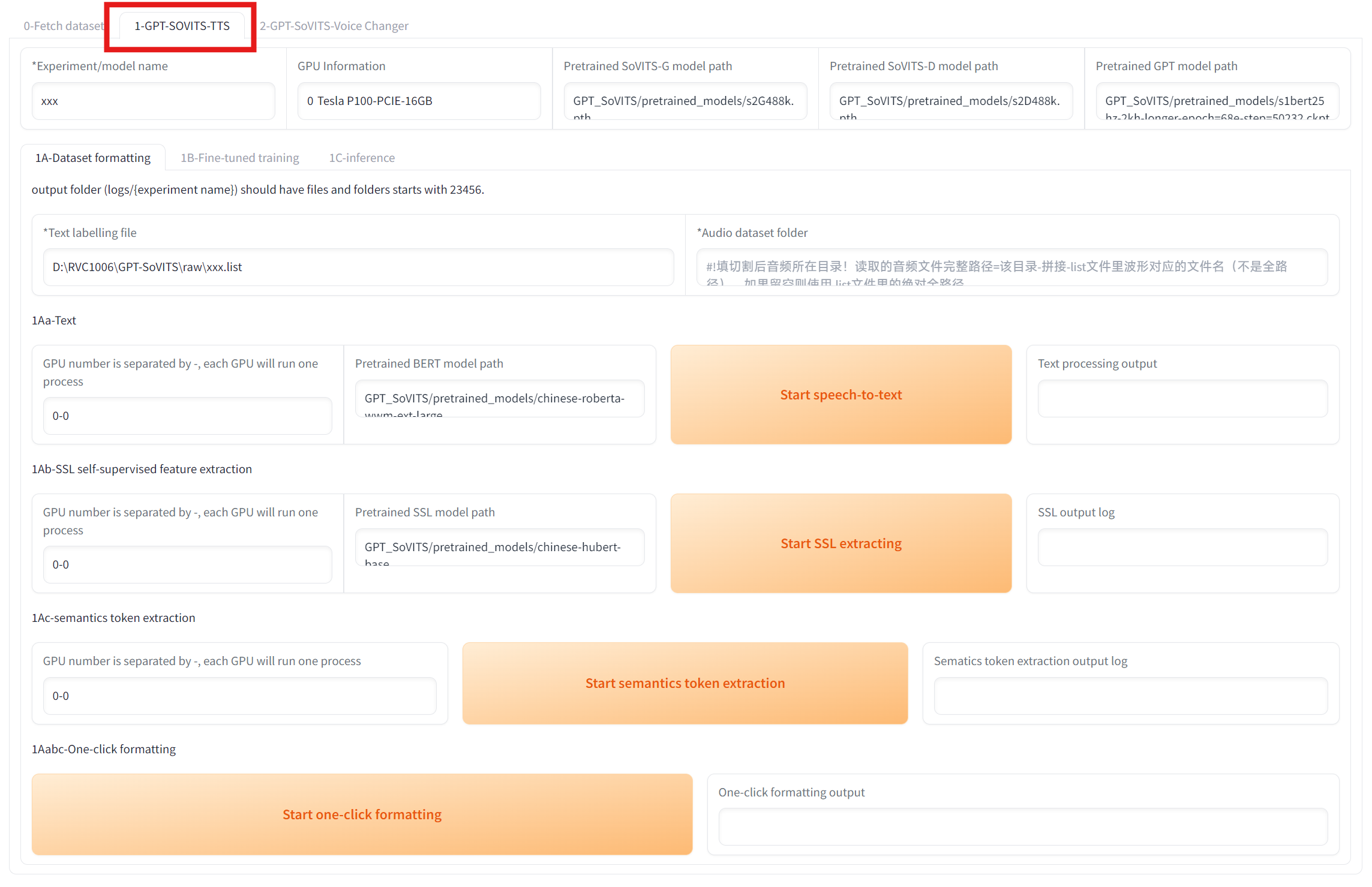
进入 1C-推理 页面

左侧选择两个你要用的模型(红色箭头),如果你要的模型没有出现,按右侧刷新模型路径按钮(黑色箭头),然后再检查。如果还是没有出现,请检查是否将模型放入了正确的目录。
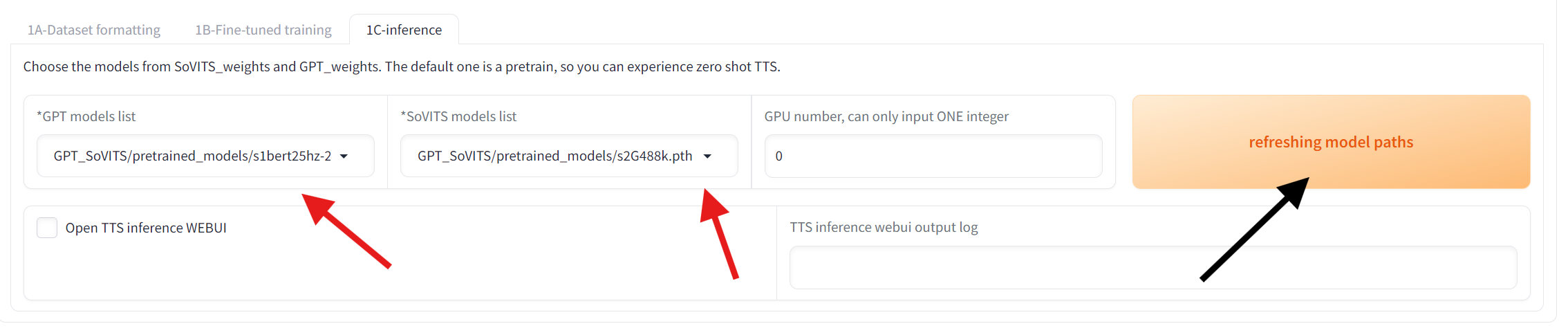
完成上述任务后勾选 打开TTS推理 WebUI,等待右侧日志输出“TTS推理进程已开启”,随后应该会跳出 http://你的IP:9872 的推理WebUI。
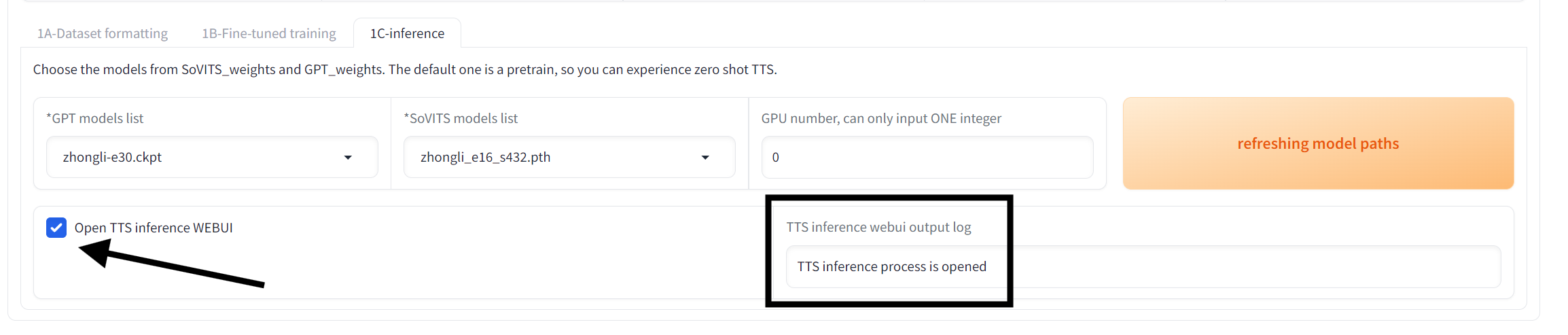
再次double check模型是否正确,如果你要的模型没有出现,按右侧刷新模型路径按钮(黑色箭头),然后再检查。如果还是没有出现,请检查是否将模型放入了正确的目录。
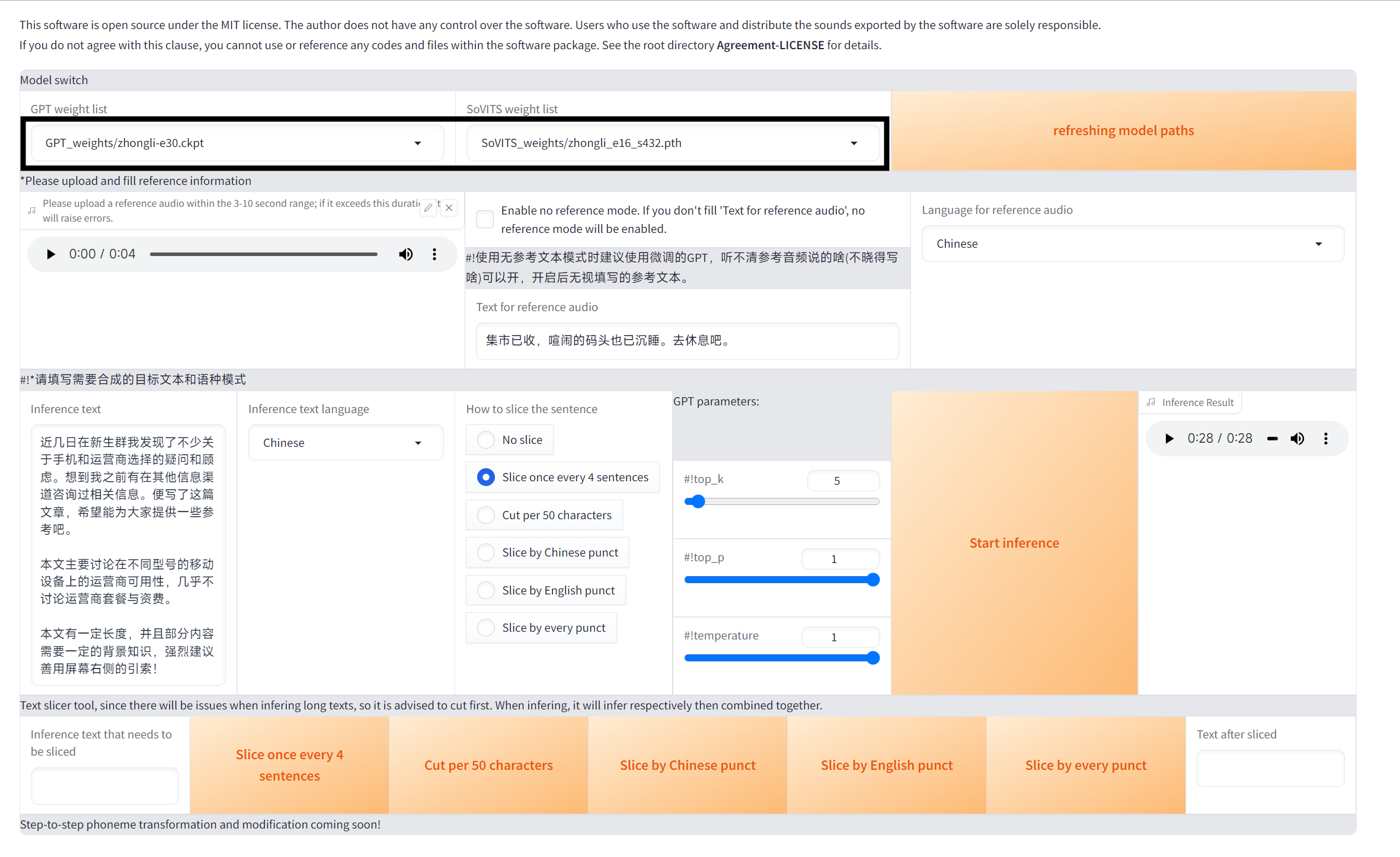
模型正确后,在右上角红色箭头的位置上传一段3-10秒的推理参考音频,并在绿色箭头的位置输入对应的参考文本,在下角蓝色方框的位置输入需要被推理的文本。随后点击开始推理,你应该能拿到一段你预期内的音频。
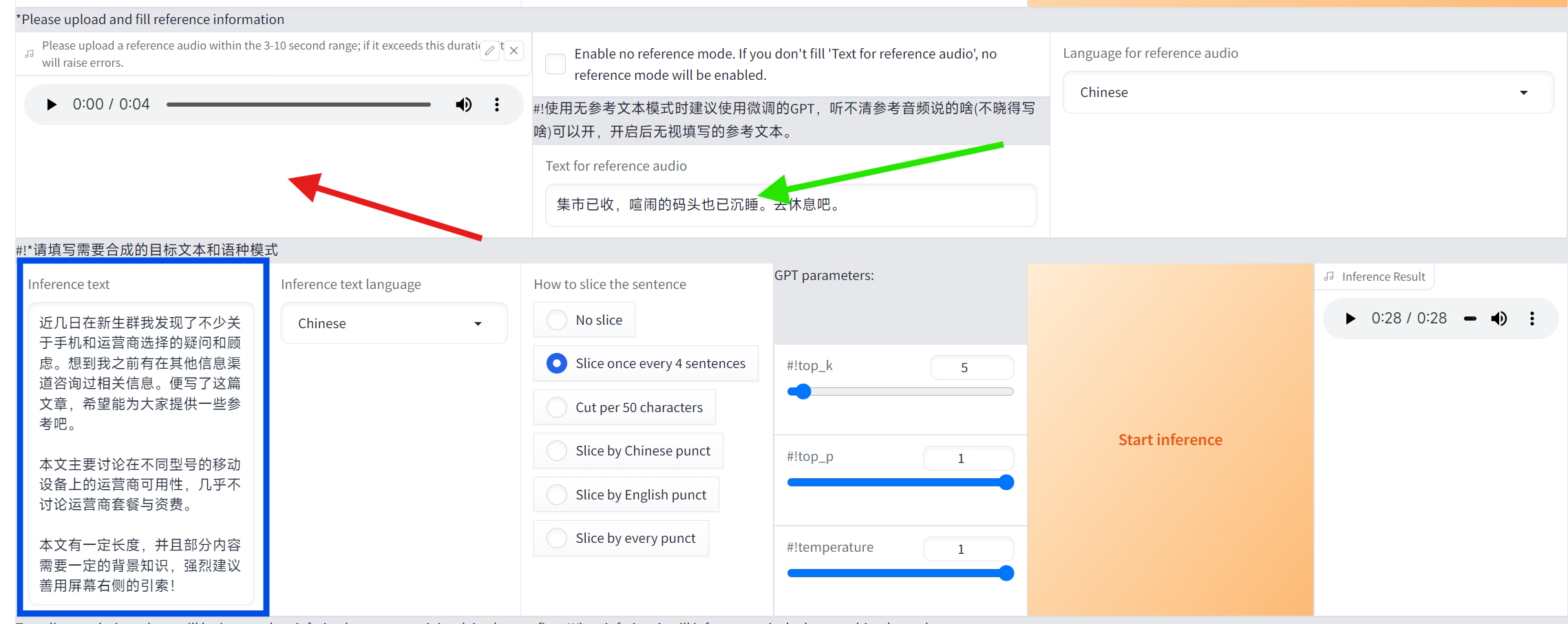
至此,推理篇告一段落。玩的开心。
训练篇
明天再写,懒。
现在就写
部分文案(尤其下面这几句)是搬的!来源在这里。
现在已支持日文训练?(存疑,看了下issue貌似没那么可用,训练出来的效果不会那么理想。
最好还是中文训练素材
素材时长1-2mins大概够用,长一些也好。但不要滥竽充数,语音质量比数量更重要(我曾用没降噪的语音训练过。个人认为效果比起后面用降噪过的/删减包含噪音的素材训练出来的效果差太多)录音格式建议wav,采样率48khz
训练音频预处理
保留人声
有需要的话可以做
引用自 这里。

切割音频
输入音频文件夹目录和输出文件夹目录,点击“Start audio slicer”
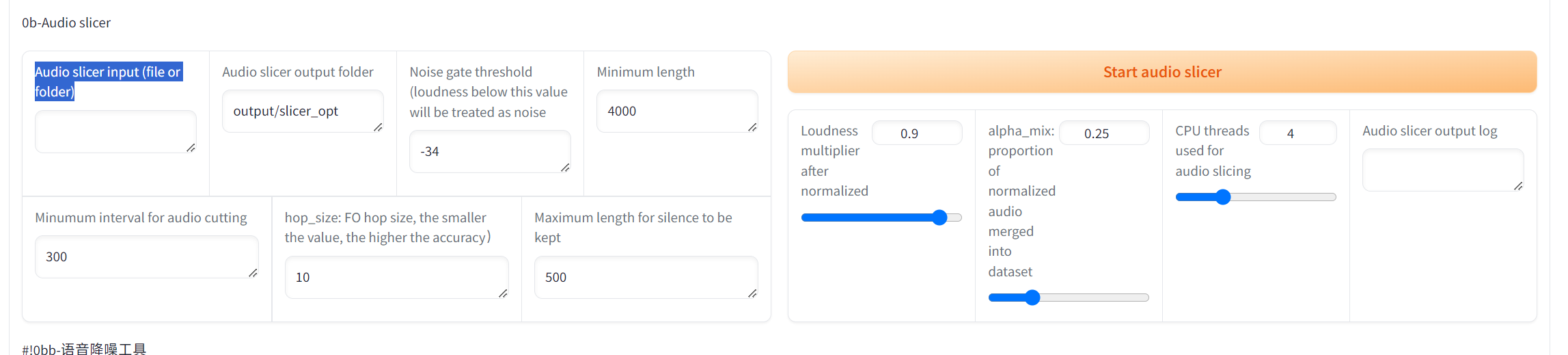
等到Log输出”切割完成“即可进入下一步
音频打标
填入切割好的音频所在的目录,并设定输出文件夹
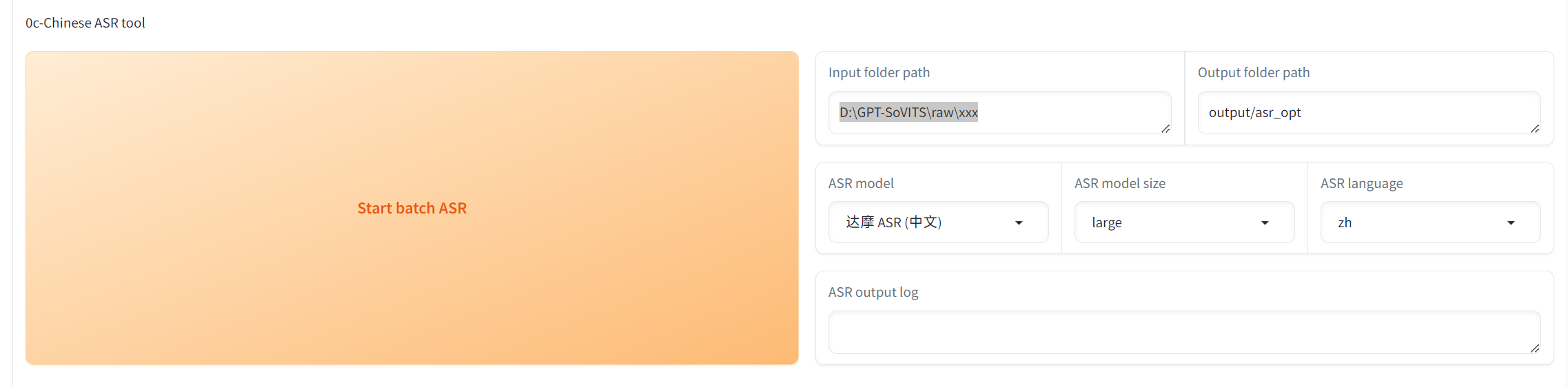
随后即可开始打标,等到Log输出“音频打标完成“即可进入下一步
音频矫对
填好打标文件所在的路径,随后勾选Open Labeling WebUI。等待WebUI启动。

注意断句要对应标点符号,每次翻页前要Submit Text保存结果。
开 始 训 练
切换到1-GPT-SOVITS-TTS页面。
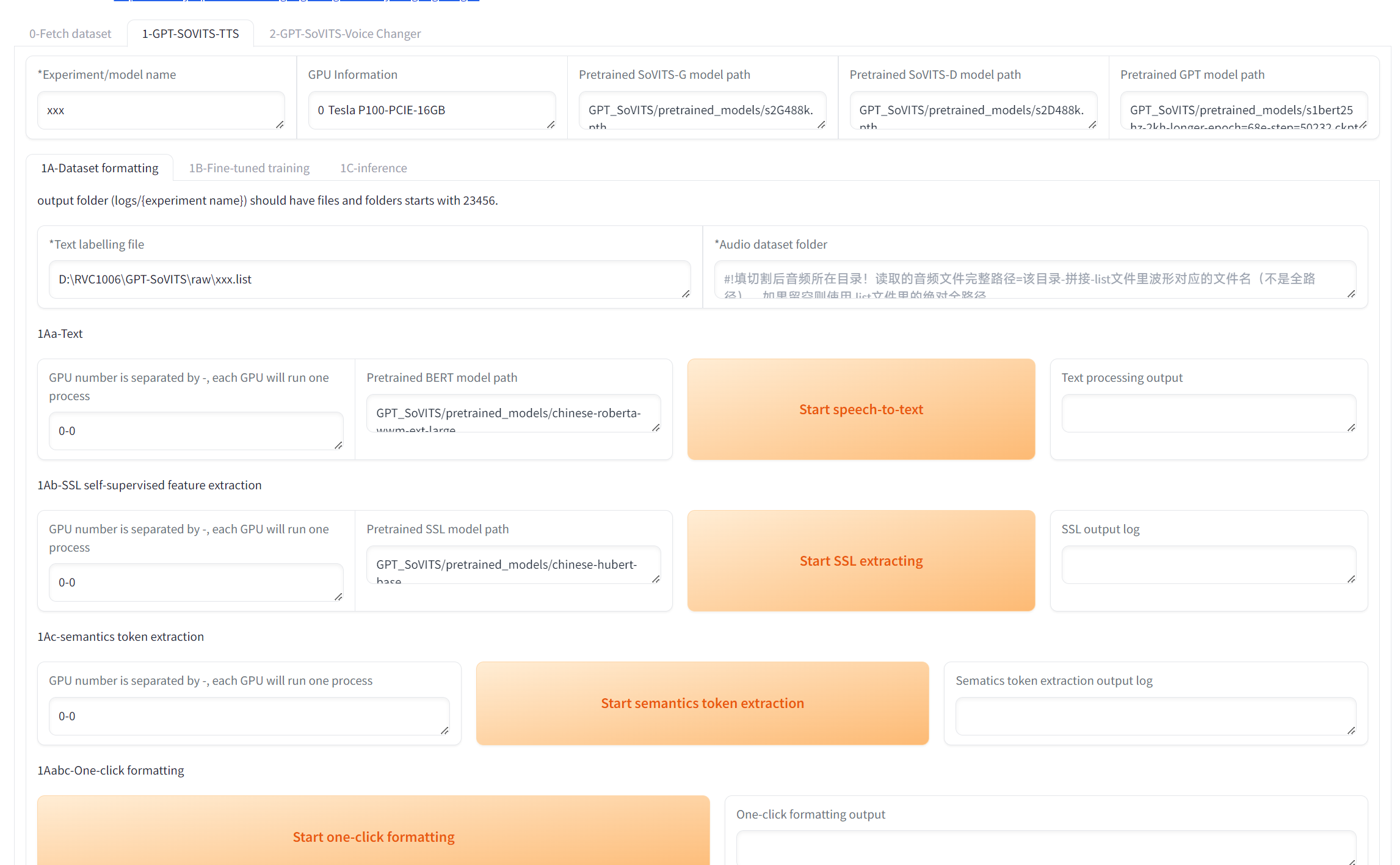
在左上角model name给你的模型取个名
然后labelling file填入打标文件,Audio dataset folder填入切割好的音频所在的目录,随后点击Start one-click formatting.
log提示进程结束即可进入下一步
进入 1B微调页面
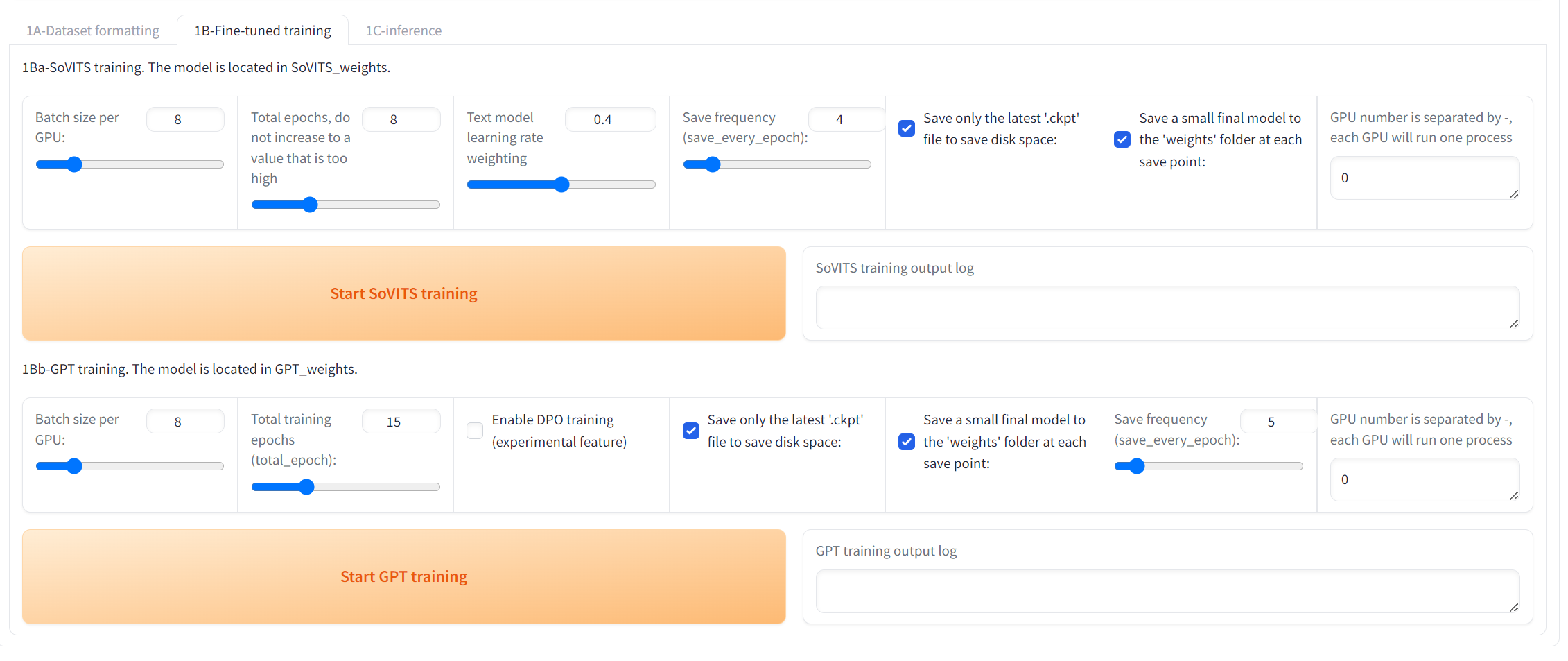
先全部参数保持默认,依次进行训练即可,如果看到CUDA out of Memory则代表爆显存了,去降低batch_size值后再训练即可。
跑完后应该可以在SoVITS_weights和GPT_weights中看到模型文件,如果没看到就没成功,可以检查下命令行输出的log
如果训练效果不好,可以拉高训练的模型论数(training epochs)。
至此,训练篇完结。Enjoy。